View Source GPT4-Vision - Extracting Data from Images
Mix.install(
[
{:instructor, path: Path.expand("../../", __DIR__)},
{:kino, "~> 0.12.3"}
],
config: [
instructor: [
adapter: Instructor.Adapters.OpenAI,
openai: [api_key: System.fetch_env!("LB_OPENAI_API_KEY")]
]
]
)Motivation
In recent months, the latest AI researcher labs have turned LLMs into multimodal models. What this means is that no longer do they just interpret text, but they can also interpret images. One example of this provided by OpenAI is the GPT4-vision-preview model. With no extra work, you can now provide images into your prompts with instructor and still do the normal structured extractions that you're used to.
In the following example, we will extract product details from a screenshot of a Shopify store.
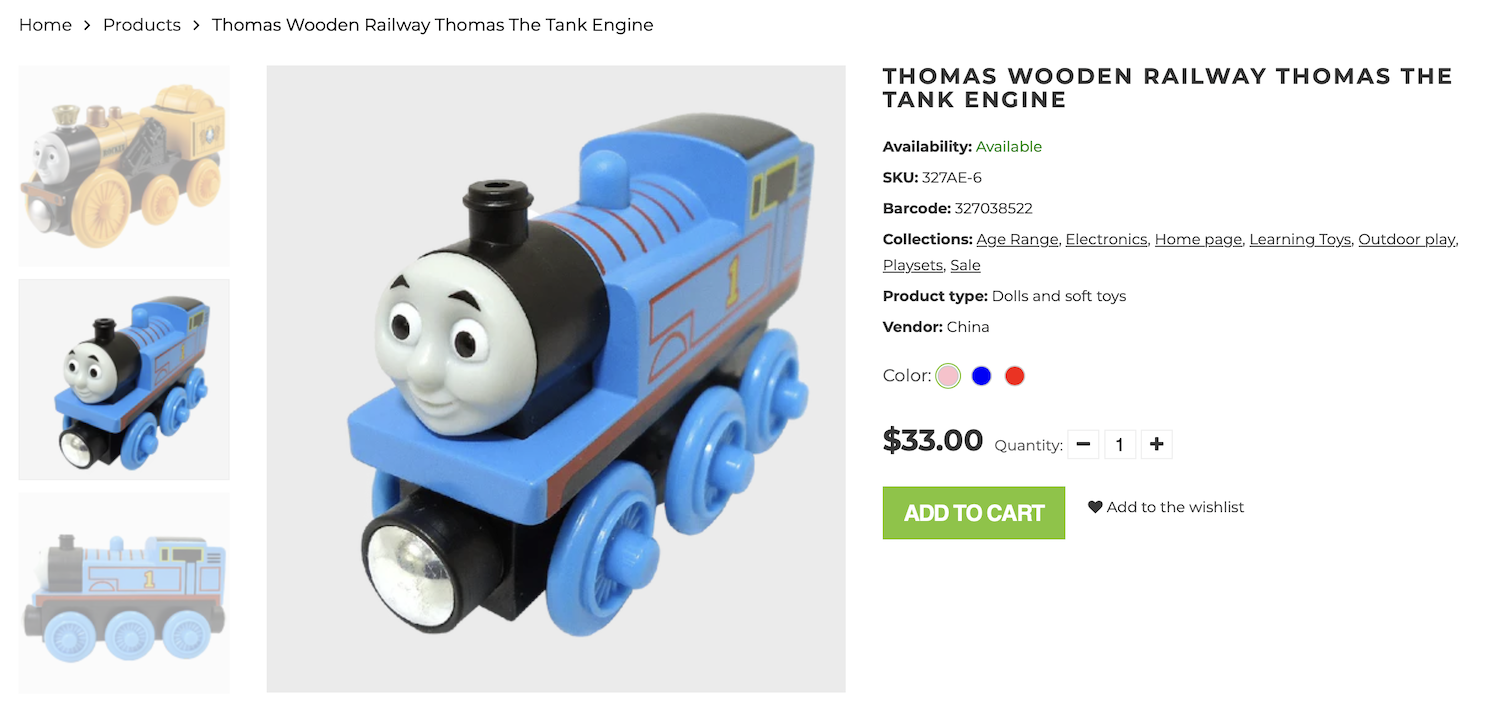
image = Kino.FS.file_path("shopify-screenshot.png") |> File.read!()
base64_image = "data:image/png;base64," <> Base.encode64(image)
defmodule Product do
use Ecto.Schema
@primary_key false
embedded_schema do
field(:name, :string)
field(:price, :decimal)
field(:currency, Ecto.Enum, values: [:usd, :gbp, :eur, :cny])
field(:color, :string)
end
end
{:ok, result} =
Instructor.chat_completion(
model: "gpt-4-vision-preview",
response_model: Product,
mode: :md_json,
messages: [
%{
role: "user",
content: [
%{type: "text", text: "What is the product details of the following image?"},
%{type: "image_url", image_url: %{url: base64_image, detail: "high"}}
]
}
],
max_tokens: 1800
)
result%Product{
name: "Thomas Wooden Railway Thomas the Tank Engine",
price: Decimal.new("33.0"),
currency: :usd,
color: "Blue"
}