| Overview |  |
kflow_gen is a meta-behavior that all parts of the pipe
(called kfnodes from this point on), such as aggregators
and demultiplexers, are built upon.
Copyright © 2019 Klarna Bank AB (publ)
This module defines the kflow_gen behaviour.
Required callback functions: init/2, handle_message/3, handle_flush/2, terminate/2.
kflow_gen is a meta-behavior that all parts of the pipe
(called kfnodes from this point on), such as aggregators
and demultiplexers, are built upon. This module implements the
following common scenarios:
initial state)Note: this behavior is considered internal, and normally it shouldn't be used directly
Some notes on terminology: modules that implement kflow_gen
behavior from now on will be referred as "intermediate callback
modules" or "intermediate CBMs". They typically define a behavior
on their own; modules that implement such behavior will be called
"user callback modules".
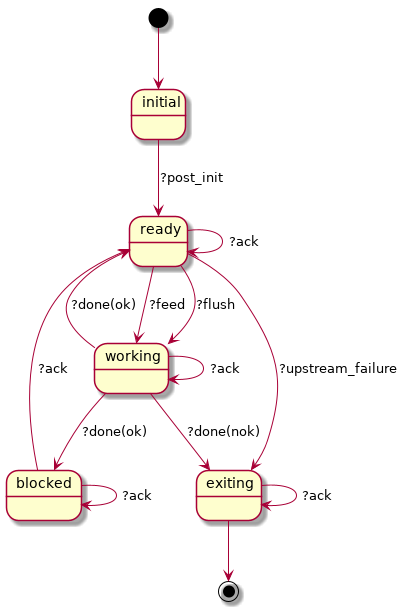
Normal workflow as seen from the perspective of a kfnode:
?feed() messages is postponed until the
state machine is in ready state. As soon as it enters this
state, it consumes one ?feed() message from the queue. Business
logic processing happens asynchronously: a temporary worker
process is spawned, it executes the behavior callback
handle_message/3 and the FSM enters working state in the
meanwhile?done({ok, Messages,
NewCbState}) message and terminates, where Messages is a
(possibly empty) list of messages that should be sent downstream
and NewCbState is the updated behavior stateready or blocked state
while the downstream is processing the messages, depending on the
number of messages and backpressure settingsmax_queue_len the kfnode can process messages from
the upstream in parallel.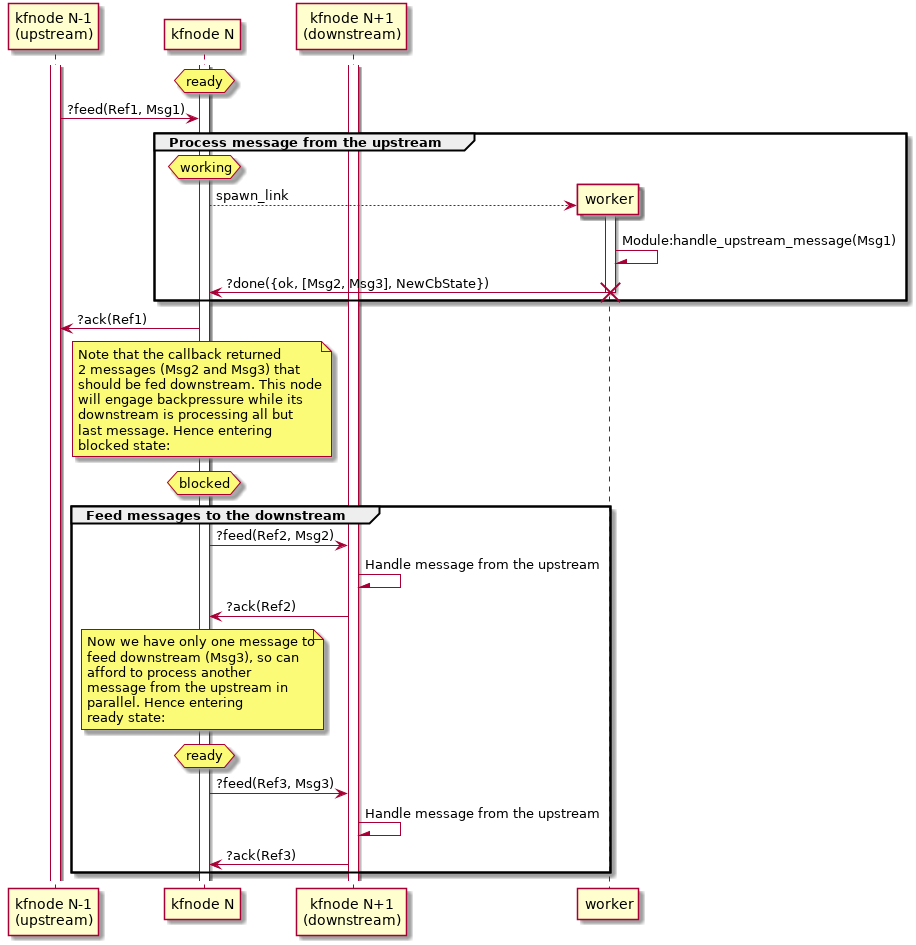
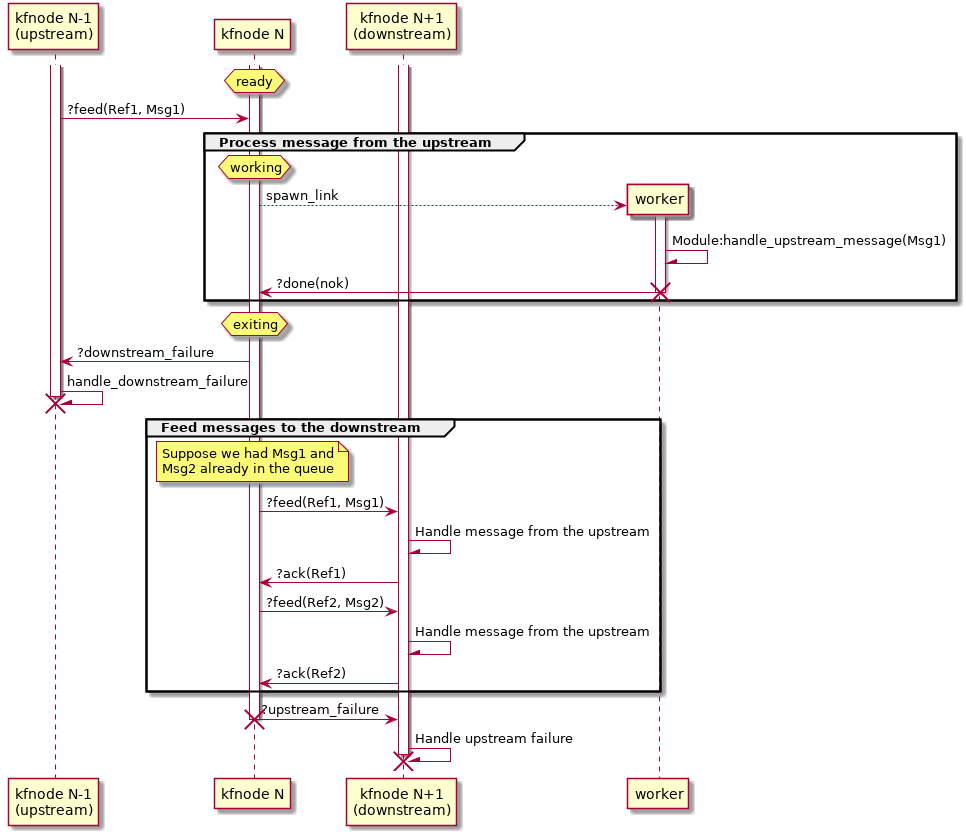
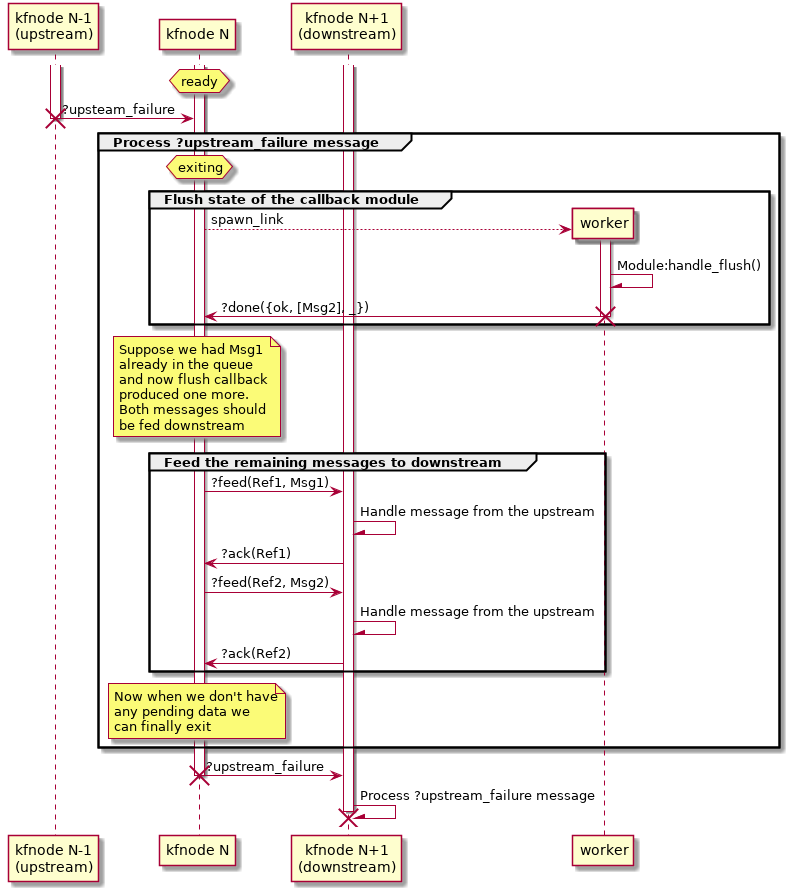
When the downstream dies, the kfnode receives
?downstream_failure message. From this point it can't do all
that much, so it just kills its worker process (if present) and
terminates.
Intermediate CBMs must follow certain rules.
First of all, intermediate CBMs are fully responsible for offset tracking. They should not advance offset of output messages too far to avoid losing data when the pipe restarts.
hidden flag of #kflow_msg record indicates that the message
should never be passed to the user CBM: from user perspective such
messages simply don't exist. However, the intermediate CBM must
ensure that offsets of hidden messages are properly accounted for
and committed. For example, when a pipe restarts, fully processed
hidden messages should not be replayed. Intermediate CBMs can set
this flag to true.
route field of #kflow_msg should not be changed, unless
intermediate CBM implements some kind of pipe splitting or joining
operation. In which case only the head of Route list may be
changed (added or removed), the tail must be preserved. Same goes
for exposing route to the user CBM: probably it's a good idea to
expose only the head of the route in order to improve
composability.
One of design choices behind kflow was making sure that data flows strictly in one direction: from upstream to downstream. This makes reasoning about kflow pipes easier and eliminates many types of concurrency bugs. However it also makes stream splitting and joining somewhat tricky to implement. The biggest problem is offset tracking: kfnode must guarantee that it won't advance offset of messages that it sends downstream beyond safe value. And the upstream may buffer up some messages for unknown period of time.
By default kflow framework solves this problem using the following
trick. Each kfnode contains multiple states of user CBM, one state
per route of upstream message. It's up to intermediate CBM to
keep track of per-route states and multiplex messages between
them.
Remember that route field of #kflow_msg{} is a list. Stream
splitting is done simply by adding a new element to the
route. Conversely, stream joining is done by removing a head of
the list. Apart from that, route field has no meaning. It is
only used to look up user CBM state.
Benefits of this solution:
Downsides of this solution:
callback_return(State) = {ret_type(), [kflow:message()], State}
ret_type() = ok | exit
| feed/4 | Send a message to the kfnode and block the caller until the message is processed by this node (but the subsequent processing is done asynchronously). |
| flush/1 | Command the node and its downstream to immediately flush all the buffered data (async call). |
| get_status/1 | Get various debug information about the node. |
| notify_upstream_failure/1 | Nicely ask node to stop. |
| post_init/2 | Tell the node pids of its neighbors. |
| start_link/1 | Start a kfnode process. |
feed(Pid::pid(), MRef::reference(), Msg::kflow:message(), Timeout::timeout()) -> ok | {error, term()}
Send a message to the kfnode and block the caller until the message is processed by this node (but the subsequent processing is done asynchronously)
Note: second argument of the function is a monitor reference of the correspondingkflow_pipe process, rather than kflow_gen
process! This is done to let internal fault handling logic run
before crashing the caller.
flush(Server::pid()) -> ok
Command the node and its downstream to immediately flush all the buffered data (async call)
get_status(Pid::pid()) -> term()
Get various debug information about the node
notify_upstream_failure(Pid::pid() | undefined) -> ok
Nicely ask node to stop
post_init(Pid::pid(), Neighbors::{_Upstream::pid(), _Downstream::pid()}) -> ok
Tell the node pids of its neighbors
start_link(Init_data::#init_data{}) -> {ok, pid()}
Start a kfnode process
Generated by EDoc