Crawly

![]()


Overview
Crawly is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
Requirements
- Elixir "~> 1.10"
- Works on Linux, Windows, OS X and BSD
Quickstart
Add Crawly as a dependencies:
# mix.exs defp deps do [ {:crawly, "~> 0.12.0"}, {:floki, "~> 0.26.0"} ] endFetch dependencies:
$ mix deps.getCreate a spider
# lib/crawly_example/esl_spider.ex defmodule EslSpider do use Crawly.Spider alias Crawly.Utils @impl Crawly.Spider def base_url(), do: "https://www.erlang-solutions.com" @impl Crawly.Spider def init(), do: [start_urls: ["https://www.erlang-solutions.com/blog.html"]] @impl Crawly.Spider def parse_item(response) do {:ok, document} = Floki.parse_document(response.body) hrefs = document |> Floki.find("a.more") |> Floki.attribute("href") requests = Utils.build_absolute_urls(hrefs, base_url()) |> Utils.requests_from_urls() title = document |> Floki.find("article.blog_post h1") |> Floki.text() %{ :requests => requests, :items => [%{title: title, url: response.request_url}] } end endConfigure Crawly
- By default, Crawly does not require any configuration. But obviously you will need a configuration for fine tuning the crawls:
# in config.exs config :crawly, closespider_timeout: 10, concurrent_requests_per_domain: 8, middlewares: [ Crawly.Middlewares.DomainFilter, Crawly.Middlewares.UniqueRequest, {Crawly.Middlewares.UserAgent, user_agents: ["Crawly Bot"]} ], pipelines: [ {Crawly.Pipelines.Validate, fields: [:url, :title]}, {Crawly.Pipelines.DuplicatesFilter, item_id: :title}, Crawly.Pipelines.JSONEncoder, {Crawly.Pipelines.WriteToFile, extension: "jl", folder: "/tmp"} ]
- By default, Crawly does not require any configuration. But obviously you will need a configuration for fine tuning the crawls:
Start the Crawl:
$ iex -S mixiex(1)> Crawly.Engine.start_spider(EslSpider)
Results can be seen with:
$ cat /tmp/EslSpider.jl
Browser rendering
Crawly can be configured in the way that all fetched pages will be browser rendered, which can be very useful if you need to extract data from pages which has lots of asynchronous elements (for example parts loaded by AJAX).
You can read more here:
Experimental UI
The CrawlyUI project is an add-on that aims to provide an interface for managing and rapidly developing spiders.
Checkout the code from GitHub or try it online CrawlyUIDemo

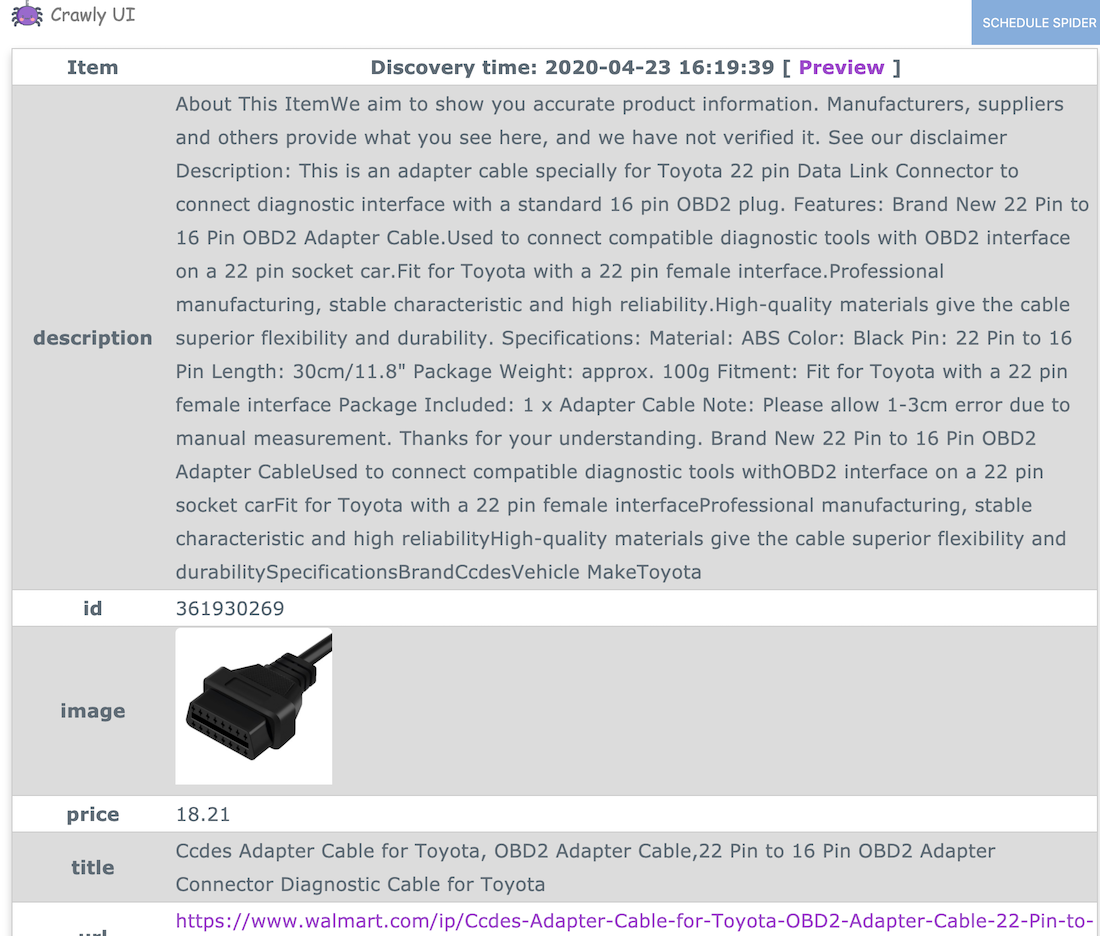

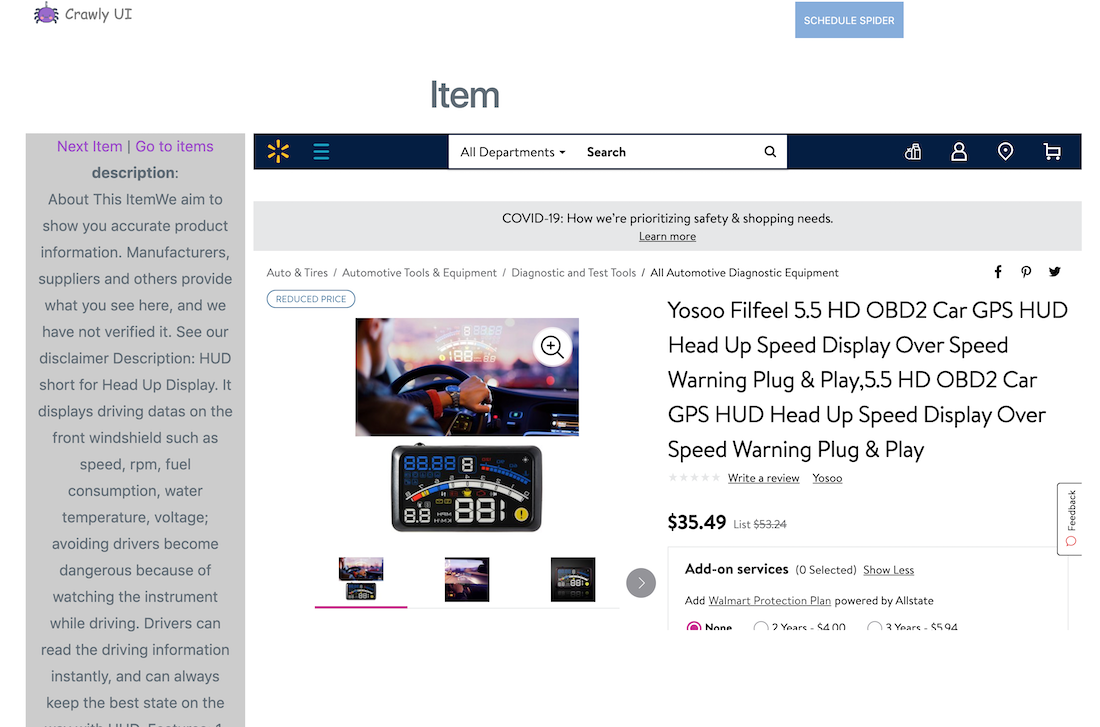
See more at Experimental UI
Documentation
Roadmap
- [x] Pluggable HTTP client
- [x] Retries support
- [x] Cookies support
- [x] XPath support - can be actually done with meeseeks
- [ ] Project generators (spiders)
- [ ] UI for jobs management
Articles
- Blog post on Erlang Solutions website: https://www.erlang-solutions.com/blog/web-scraping-with-elixir.html
- Blog post about using Crawly inside a machine learning project with Tensorflow (Tensorflex): https://www.erlang-solutions.com/blog/how-to-build-a-machine-learning-project-in-elixir.html
- Web scraping with Crawly and Elixir. Browser rendering: https://medium.com/@oltarasenko/web-scraping-with-elixir-and-crawly-browser-rendering-afcaacf954e8
Example projects
- Blog crawler: https://github.com/oltarasenko/crawly-spider-example
- E-commerce websites: https://github.com/oltarasenko/products-advisor
- Car shops: https://github.com/oltarasenko/crawly-cars
- JavaScript based website (Splash example): https://github.com/oltarasenko/autosites
Contributors
We would gladly accept your contributions!
Documentation
Please find documentation on the HexDocs
Production usages
Using Crawly on production? Please let us know about your case!