View Source Zero Cost Distribution
Cloister provides a callback on cluster topology changes, which makes it easy to perform some additional setup when the cluster is up.
But what if we want to distribute our processing without actually writing the support for running in distributed mode? For that one might use Tarearbol.DynamicManager abstraction.
Let’s say we receive gazillions of messages from some message broker and need to process them asynchronously. The typical application would use Cloister as the cluster manager and Tarearbol.DynamicManager as the workload processor. Our goal would be to build absolutely transparent system, allowing horizontal scaling out of the box. We cannot just spawn another node in a hope that everything would be fine because the processor is determined by a HashRing backed up by Cloister and the message would be fed from the message broker by the random—currently available—node. Of course we might ask Cloister about who is to process this message, and send the message directly to this process, but this would potentially suffer from back pressure issues either blocking the broker queue, or overflowing the target process mailbox.
The easiest solution would be to store incoming messages in local store, that would be consumed by our workers. The dataflow would look somewhat like
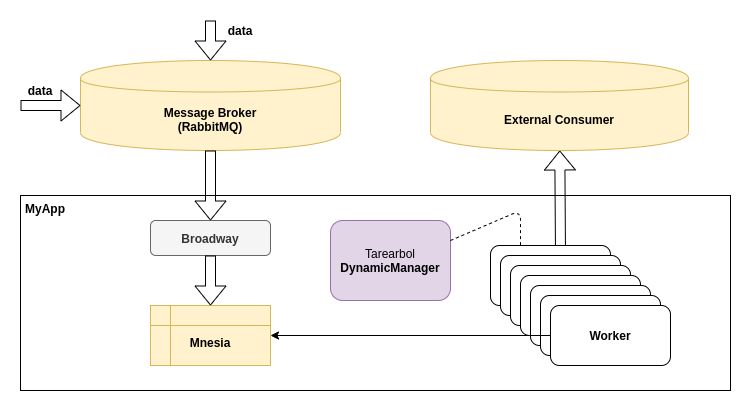
That would be a no-brainer at all, if we were working in legacy running instances. But here we have a dockerized environment. Containers might appear, and disappear almost at random. And we want to handle each topology change gracefully.
Topology Change Listener
First of all, we need to supply our own inmplementation of topology change listener, as described in Configuration.
config :cloister,
otp_app: :my_app,
listener: MyApp.CloisterListener,
...And the boilerplate for the implementation would be that
defmodule MyApp.CloisterListener do
@moduledoc false
@behaviour Cloister.Listener
require Logger
@impl Cloister.Listener
def on_state_change(_from, %Cloister.Monitor{status: :up}) do
Logger.info("Cluster is up")
end
def on_state_change(from, %Cloister.Monitor{status: status}) do
Logger.debug("Cluster state change #{from} → #{status}")
endSo far, so good. Now we want to support distributed mnesia here. Let’s suppose we might survive several seconds blackout on topology changes, and we use this mnesia as a cache, so it does not contain billions of records. We would simply load the existing cache content into memory, recreate mnesia for new topology and feed it with the data from memory. There are many more elegant and robust solutions, but for our demonstration purposes that scenario is perfectly fine.
Let’s change the former on_state_change/2 clause to do that.
@impl Cloister.Listener
def on_state_change(_from, %Cloister.Monitor{status: :up}) do
this = node()
others = Node.list()
nodes = [this | others]
# voluntarily select a master node
if match?([^this | _], Enum.sort(nodes)) do
load_data_into_memory() # the implementation is out of scope
Enum.each(@tables, :mnesia.delete_table/1)
:mnesia.stop()
:mnesia.delete_schema(nodes)
:mnesia.create_schema(nodes)
:mnesia.start()
Enum.each(@tables, &:mnesia.create_table(&1, disk: nodes))
:mnesia.wait_for_tables(@tables)
load_data_from_memory() # the implementation is out of scope
# deploy this to other nodes
unless nodes == [this] do
:mnesia.change_config(:extra_db_nodes, others)
Enum.each(others, &:mnesia.change_table_copy_type(:schema, &1, :disc_copies))
for table <- :mnesia.system_info(:tables),
table in @tables,
{^this, type} <- :mnesia.table_info(table, :where_to_commit),
do: Enum.each(others, &:mnesia.add_table_copy(table, &1, type))
end
end
endWe are done! Now the topology change would enforce the renewal of mnesia configuration. It surely might be done in more sophisticated way by e. g. deleting schemas on remote nodes and restarting mnesia there, but this is also good enough.
OK, it’s now time to serve processors.
DynamicManager Implementation
As described in the documentation, Tarearbol.DynamicManager expects a worker definition. Let’s provide it.
defmodule MyApp.WorkProcessor do
@moduledoc false
use Tarearbol.DynamicManager
@impl Tarearbol.DynamicManager
def children_specs do
# start million processes, handling entities named like "foo_42"
for i <- 1..1_000_000, do: {"foo_#{i}", []}, into: %{}
end
@impl Tarearbol.DynamicManager
def perform(foo, payload) do
if Cloister.mine?(foo),
do: {:replace, foo, perform_work()},
else: {:ok, DateTime.utc_now()}
end
@impl Tarearbol.DynamicManager
def handle_state_change(state), do: state
@impl Tarearbol.DynamicManager
def handle_timeout(_state), do: :ok
@spec perform_work :: [any()]
defp perform_work do
for record <- :mnesia.select(...), do: ...
end
endWe are all set now. Once came from the broker, the message gets stored in mnesia. Then the worker for this key gets the message(es) from there and does whatever it needs.
When the new node is being added/removed, Cloister would change the state into :rehashing, rebuild the mnesia database and continue processing messages with a new cluster topology.